Building my first R package
Recently, I began working with time series and found myself searching for a way to build confidence intervals around certain statistics I was interested in, like a series’ median. Many time series do not follow a known probability distribution so my mind went directly to using a bootstrap to estimate a sample variance. Here’s what I learned:
The Bootstrap Method
The bootstrap is a statistical technique used to infer characteristics of a population with a very limited set of assumptions about the sample data. The bootstrap does not require one to know (or guess) the underlying probability distribution of the data, and this is one of its greatest advantages. Using the bootstrap method, inference can be made without specifying any functional form. However, the assumptions that the regular bootstrap does require can be quite limiting in certain contexts like time series.
These contexts often present problems when observations are not independent and identically distributed (i.i.d.), a critical assumption of the regular bootstrap. The implications of the i.i.d. assumption are quite strong. We can say that observations are independent of eachother when the value of one observation has no effect on the value of other observations. This also means if we reorder the set of current observations this would have no effect on future observations, which is often not the case with time series.
One example of this is a random survey of individuals’ height. Certainly, there are characteristics that can influence how tall a person may be, such as age - but ultimately as we collect survey responses, the height of one respondent should not have an effect on the height of other respondents. In this sense, we can say that our survey responses are independent from each other. I will not go into all the implications of i.i.d. assumptions here, but I will say that topic of natural characteristics such as human heights being i.i.d. is full of nuance drawing out some of the implications such powerful statistical assumptions manufacture. If you would like to learn more, I encourage you to check out these posts on Why heights are normally distributed and Why heights are not normally distributed.
Why i.i.d. fails
Let’s continue our random survey of human heights. For the next few years, we send out the height questionnaire every year to each randomly-selected respondent from our original survey. The data from the survey each year will be compiled into panel-data where respondents’ heights can now be tracked over a period of several years.
We have more data than had we just conducted the first survey, so we should be able to make stronger inferences than before, right? Well, not exactly. If we begin to conduct inferences about all human heights (population characteristics) using this collection of panel-data, we fail to recognize the underlying connections that have been introduced.
When we survey the same group of (originally) randomly-selected respondents each year, the height of a respondent this year should be related to their height in the previous year. Since humans generally grow in one direction we would expect the average height in our survey to only increase or stay relatively the same each year. This dynamic now violates our assumption of independence within the sample because each respondent’s answers will be connected. Panel-data and other types of data with inherent connections is characterized as dependent data.
In practice, we could modify our survey design to target a different group of respondents each year removing such dependencies. However, this example illustrates a situation often encountered in time series analysis where processes are tracked over time and we cannot simply find unrelated processes within the data to help us answer questions about the original one.1
In general, i.i.d. assumptions fail for many types of time series because we would expect the observation in the previous period to have some explanatory power over the current observation. I refer to this phenomenon as time-dependence, and it can could occur in many time series from unemployment rates, stock prices, biological data, etc. For example, we expect the water level of a river today to be somewhat close to the water level yesterday. The farther away from yesterday we go, the less related future water levels will be.
Time-Dependence
We can visualize what the i.i.d assumption looks like in time series by comparing time series with varying degrees of dependence on past observations. A time series that is completely i.i.d. looks like white noise, since each observation is completely random. We can compare this to a simulated time series with various degrees of time-dependence:
# Generate i.i.d. time series
white.noise <- ts(rnorm(500))
# Generate AR(1) simulation
ar1.series <- arima.sim(model = list(order = c(1, 0, 0),
ar = 0.5), n = 500, rand.gen = rnorm)
# Generate AR(5) simulation
ar5.series <- arima.sim(model = list(order = c(5, 0, 0),
ar = c(0.2, 0.2, 0.1, 0.1, 0.1)), n = 500)
# Combine with time period
series <- data.frame(
"Time" = rep(1:500, 3),
"Series" = factor(c(
rep("White Noise", 500),
rep("AR(1)", 500),
rep("AR(5)", 500)),
levels = c("White Noise", "AR(1)", "AR(5)")),
"Value" = c(white.noise, ar1.series, ar5.series)
)Behind the scenes, I plot these three time series:
The top panel illustrates a perfectly i.i.d. time series, while the bottom two panels illustrate time series where each observation is somewhat dependent on the previous observations. These are called autoregressive \(AR(p)\) processes of order \(p.\) The order of the \(AR\) process defines the number of prior observations \(p\) which have explanatory power over the current observation. The middle panel illustrates an \(AR(1)\) simulation, thus each observation depends on only the immediate prior observation. The bottom panel illustrates an \(AR(5)\) model with a higher autoregressive order where each observation is dependent on the previous five observations.
To some extent we can see the degree of time-dependence in each model. The top panel seems to oscillate much quicker and the periods of downward/upward trend are relatively short. If we compare this to the \(AR(1)\) model, somewhat more pronounced trends appear where observations are increasing or decreasing consistently for longer durations. In the \(AR(5)\) model, these trends seem even more drawn out. Though we can try to make visual comparisons because we understand the data-generating process behind these three time-series, in practice, this is often not the case and we must employ a battery of statistical tests to infer the degree of dependence — if any — within a given series.
The Block Bootstrap
To get around this problem, we can retain some of this time-dependence by breaking-up a time series into a number of blocks with length \(l\). Instead of sampling each observation randomly (with replacement) as in a regular bootstrap, we can resample these blocks at random. This way within each block the time-dependence is preserved. Below is a diagram from El Anbari, Abeer, and Ptitsyn (2015) on a common block bootstrap method, the moving block bootstrap (MBB).
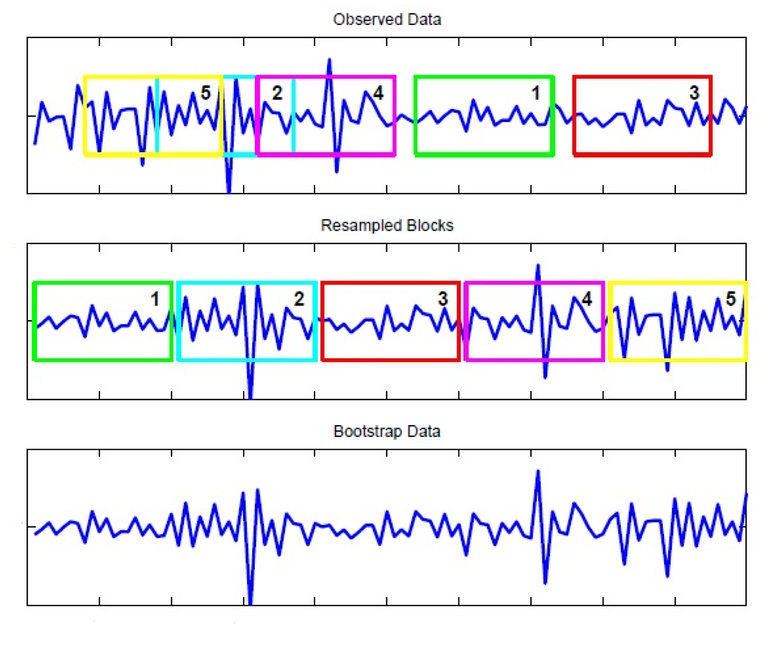
In the moving block bootstrap, blocks are sampled from a set of overlapping blocks placed on top of the original time series. We can see this in the top panel where the yellow (5) and magenta (4) blocks both overlap with the cyan (2) block. In practice, a series of overlapping blocks will be laid over one another where each block increments one observation forward from the previous block, so that a total of \(n-l+1\) blocks of length \(l\) are laid over a time series with \(n\) observations.2 A block bootstrap of this scheme is known as Künsch’s rule.3
The problem with the block bootstrap is the high sensitivity to the choice of block-length. If we decide to use blocks of half the length or double the length as depicted above, our bootstrap data may change dramatically and in turn any inference we perform.
This was exactly the problem I ran into several weeks ago working with benchmark interest rates. My plan was to use tseries::tsbootstrap() to block bootstrap the rates, but I found the results varied dramatically when I changed the block-length — and even worse — I had no reasoning to defend whatever block-length I selected.
Choosing a Block-Length
A hard-and-fast rule for the parameterization of block-length is still an unsolved problem; However, a variety of methods have been proposed in the econometric and statistical literature. I was able to find a selection of plug-in rules and algorithms to assess optimal blocks-lengths under various criteria.4 In their seminal paper, Hall, Horowitz, and Jing (1995) show that the optimal asymptotic formula for block-length is proportional to \(n^{\frac{1}{k}}\) where \(k=\{3,4,5\}\) depending on the desired object of estimation.5 Moreover, Hall, Horowitz, and Jing (1995) develop an empirically based algorithm to optimize the choice of block-length.
This was exactly what I needed, but a bit searching around CRAN, GitHub, and STATA and SAS libraries came up with nothing.
Enter blocklength
The goal of blocklength is to simplify and automate the process of selecting a block-length to bootstrap dependent data. blocklength is an R package with a set of functions to automatically select the optimal block-length for a bootstrap of suitable dependent data, such as stationary time series or dependent spatial data.
Currently, there are two methods available:
hhj()takes its name from the Hall, Horowitz, and Jing (1995) “HHJ” method to select the optimal block-length using a cross-validation algorithm which minimizes the mean squared error \((MSE)\) incurred by the bootstrap at various block-lengths.pwsd()takes its name from the Politis and White (2004) Spectral Density “PWSD” Plug-in method to select the optimal block-length using spectral density estimation via “flat-top” lag windows of Politis and Romano (1995).
Under the hood, hhj() uses the moving block bootstrap (MBB) procedure according to Künsch’s rule, which resamples blocks from a set of overlapping sub-samples with a fixed block-length. However, the results of hhj() may be generalized to other block bootstrap procedures such as the stationary bootstrap of Politis and Romano (1994).
Compared to pwsd() , hhj() is more computationally intensive as it relies on iterative resampling processes that optimize the \(MSE\) function over each possible block-length (or a select grid of block-lengths). pwsd() is a simpler “plug-in” rule that uses the auto-correlations, auto-covariance, and the subsequent spectral density of the series to optimize the choice of block-length.
Currently, only the HHJ and PWSD methods are implemented through these two functions, but I plan on adding additional block-selection methods such as the Jackknife-after-bootstrap (JAB) Nonparametric Plug-in method proposed by S. N. Lahiri, Furukawa, and Lee (2007).6
The package can be downloaded from my GitHub.
If you are interested in more infoRmation, make sure to checkout R-bloggers where you can find this post and many more!
References
Other common contexts for dependent data include spatial information such as topographical data or biological data, such as measuring biological oxygen demand (BOD) levels in rivers.↩︎
We assume that there are \(b\) blocks of length \(l\) such that \(bl \sim n\) for simplicity.↩︎
For a thorough treatment of bootstrapping methods for dependent data and the selection of optimal block-length, See S. K. Lahiri (2003).↩︎
Specifically, \(n^{\frac{1}{3}}, n^{\frac{1}{4}},\) and \(n^{\frac{1}{5}}\) are used in the estimation of bias or variance, the estimation of a one-sided distribution function, and the estimation of a two-sided distribution function, respectively.↩︎
Both
pwsd()andhhj()have output corresponding ‘pwsd’ and ‘hhj’ class objects which may be passed into S3 plotting methods. The usage of this package will be discussed in a later post.↩︎